

Computer Vision is a scientific approach through which computers can understand digital images or videos, With the help of deep learning it enable machines to visualize and see things as like humans.
Below is the list of datasets which can be practiced while working on computer-vision projects to enhance user experience.
A*3D – Autonomous Driving Dataset

Self-driving cars largely exploit supervised machine learning algorithms to perform tasks such as 2D/3D object detection. Existing autonomous driving data-sets represent relatively simple scenes with low scene diversity, low density and are usually captured in day-time.
Training and bench-marking detection algorithms on these datasets lead to lower accuracy when applying them in real-world settings, making it unsafe for the public. With the increasing use of autonomous vehicles, it is important for these data-sets to not only represent different weather and lighting conditions but also contain challenging high-density diverse scenarios.
A new challenging A*3D dataset is proposed for autonomous driving in the real world with highly diverse scenes, attributed to the large spatial coverage of the recording, high driving speed, and low annotation frequency.
Boxy Vehicle Data Set
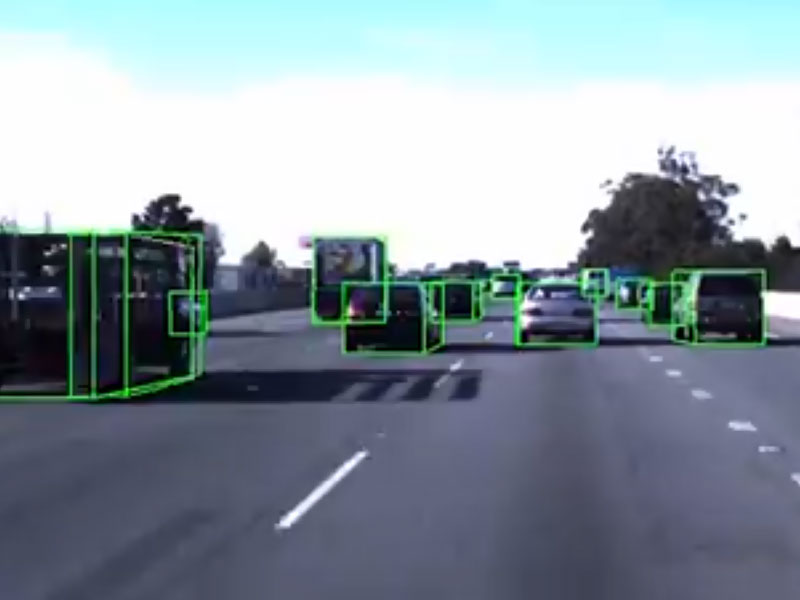
Boxy is one of the largest public vehicle detection datasets with 1.99 million annotated vehicles in 200,000 images, including sunny, rainy,and nighttime driving. If possible, vehicle annotations are split into their visible sides to give the impression of 3Dboxes for a more accurate representation with little over-head. Five megapixel images with annotations down to a few pixels make this dataset especially challenging.
Camera images generally offer a higher resolution com-pared to various sensors such as lidar or radar. This allows an understanding of a vehicle’s complete surrounding and object detection’s over long distances. Color information can additionally be used to deduce attributes, such as brake lights and turn signals, which are not available in other sensors. A lot of advances in computer vision and vehicle detection are possible because of public datasets and bench-marks.
Google Landmarks Dataset Ver2

Google Landmarks dataset (GLD-v2), contains images annotated with labels representing human-made and natural landmarks. The dataset can be used for landmark recognition and retrieval experiments. This version of the dataset contains approximately 5 million images, split into 3 sets of images: train, index and test.
Generated Faces

Above people aren’t real!
Generated Media, Inc are building the next generation of media through the power of AI. Copyrights, distribution rights, and infringement claims will soon be things of the past. ‘Generated Media’ created a free resource of 100k high-quality faces. Every image was generated by internal AI systems as it continually improves. Use them in your presentations, projects, mockups or wherever — all for just a link back to us!
Driving Dataset

Audi-electronics have published the AEV Autonomous Driving Dataset (A2D2) to support startups and academic researchers working on autonomous driving. Equipping a vehicle with a multimodal sensor suite, recording a large dataset, and labelling it, is time and labour intensive. Our dataset removes this high entry barrier and frees researchers and developers to focus on developing new technologies instead. The dataset features 2D semantic segmentation, 3D point clouds, 3D bounding boxes, and vehicle bus data.
MinneApple

A Benchmark Dataset for Apple Detection and Segmentation
A new dataset to advance the state-of-the-art in fruit detection, segmentation, and counting in orchard environments. While there has been significant recent interest in solving these problems, the lack of a unified dataset has made it difficult to compare results. MinneApple hope to enable direct comparisons by providing a large variety of high-resolution images acquired in orchards, together with human annotations of the fruit on trees. The fruits are labeled using polygonal masks for each object instance to aid in precise object detection, localization, and segmentation.
Additionally, MinneApple provide’s data for patch-based counting of clustered fruits. The dataset contains over 41, 000 annotated object instances in 1000 images. A detailed overview of the dataset is presented together with baseline performance analysis for bounding box detection, segmentation, and fruit counting as well as representative results for yield estimation.
Replica Dataset

The Replica Dataset is a dataset of high quality reconstructions of a variety of indoor spaces. Each reconstruction has clean dense geometry, high resolution and high dynamic range textures, glass and mirror surface information, planar segmentation as well as semantic class and instance segmentation.
NightOwls – Pedestrian detection at night

Detecting and tracking people is one of the most important applied problemsin computer vision. Significant applications such as entertainment, surveillance,robotics, and assisted and automated driving, are all centered around people.They thus require highly-reliable people detectors that can work in a variety ofindoor and outdoor scenarios and are robust to challenging visual effects suchas variable appearance, inhomogeneous illumination, low resolution, occlusionsand limited field of view. The NightOwls Dataset focuses on pedestrian detection at night.
Waymo Open Dataset

The Waymo Open Dataset is comprised of high resolution sensor data collected by Waymo self-driving cars in a wide variety of conditions. We are releasing this dataset publicly to aid the research community in making advancements in machine perception and self-driving technology.
Hopefully above post gives a little hint on datasets and how these datasets can be best utilized for the betterment of human society.


